A pair of Wisconsin academics note the Pope’s sentiments capture concerns over the explosion of artificial intelligence at a time when public policy isn’t keeping pace.
This article was produced by the nonprofit journalism publication Bolts, which covers the nuts and bolts of power and political change, from the local up.
The Dane County Sheriff’s Office will stop using dozens of AI surveillance cameras posted up across Madison and surrounding towns, after the county Board of Supervisors pulled funding from a contract with Flock Safety, the latest setback in this state for the Atlanta-based tech company.
Flock has swiftly grown a sprawling, nationwide network of cameras that photograph passing cars and use AI to track their movements with precision, with thousands of law enforcement agencies installing Flock cameras in exchange for access to the company’s database. But many local governments are nowbreakingoff their agreements with Flock after numerous instances where the cameras were misused and breached, or where the data they collected ended up in ICE’s hands.
Within Dane County, the cascade started when the city of Verona pulled its three automated license plate readers from the Flock network in November, after police officers elsewhere in the country accessed Verona’s cameras on behalf of immigration agents. Bolts previously reported that Flock ignored demands by Verona officials to take down the cameras for months after they ended the contract, and the city eventually covered the surveillance cameras with black plastic bags to protect residents’ privacy. Verona Mayor Luke Diaz told Bolts at the time that the county government’s contract with Flock was “the next big domino” to fall in Wisconsin.
Verona’s representative on the Dane County Board, Supervisor Chad Kemp, then proposed defunding the sheriff’s agreement with Flock, and the board voted 32-1 in April to strip $80,000 from the budget allocated to paying for the cameras. Sheriff Kalvin Barrett’s office confirmed to Bolts via email on April 30 that he will abide by the board’s wishes and cease using Flock.
Dane County Sheriff Kalvin Barrett contracted with the tech surveillance company Flock Safety without the approval of the county board. His office says it’s considering alternatives to Flock after the county board pulled funding. He is shown at the Wisconsin State Capitol during a May 21, 2021, meeting of the Speaker’s Task Force on Racial Disparities Subcommittee on Law Enforcement Policies and Standards. (Will Cioci / Wisconsin Watch)
Other Wisconsin cities have dropped their Flock contracts since Dane County’s vote, including Monona, a suburb of Madison, and Oshkosh, in Winnebago County, where the police chief not just ended the contract but also covered cameras in plastic bags after Flock allegedly misrepresented how its data was used.
Diaz is heartened by this ongoing domino effect that’s rocking Wisconsin. “If police chiefs are bailing on it, that really shows momentum,” he saidin a follow-up interview this month. “I feel like, at least politically, it is a sign that we’re winning.”
“It really shows that local activists can make a really big difference,” he said. “Small communities can be laboratories of democracy, and we can stand up to be an example for other communities.”
Now privacy activists are pushing to remove Wisconsin’s remaining Flock cameras, including those operated by the Milwaukee Police Department and by the University of Wisconsin-Madison police.
But beyond targeting any specific Flock contract, they’re also pressuring local officials across the state to set proactive guardrails around AI surveillance technologies.
They hope to stop law enforcement agencies from responding to their wins against Flock by just turning to Flock’s competitors to install similar systems of automated license plate readers (ALPRs).
A spokesperson for the Dane County Sheriff’s Office told Bolts that the office is already exploring other vendors to replace Flock.
Law enforcement agencies often deploy invasive technologies like ALPRs without notifying the people being spied on and without approval from elected officials, said Jon McCray-Jones, a policy analyst with the ACLU of Wisconsin. He warns that, without robust protections limiting what police can do, residents will be “playing a game of Whack-A-Mole with surveillance companies” as police seek lesser-known companies like Motorola.
“We’re starting to miss the forest for the trees, where the conversation has been about how bad Flock is,” McCray-Jones told Bolts. “Sure, the headline changes with a slightly better company. But the innate issues around ALPRs don’t. You still have similar cameras, similar databases, similar mass, warrantless tracking. You just have a different logo on the contract.”
The Dane County sheriff was able to install the Flock system initially without getting approval from the board since it was paid for by a $68,750 grant funded by a separate surveillance company, Axon Enterprise. Axon used to have a partnership with Flock but has since severed it. The sheriff’s spokesperson ruled out seeking outside funding again.
Jade, a Madison resident and privacy advocate who created Deflock Dane, a project that maps the cameras that watch over the area, warns that a new technology could just as easily be installed to replace the Flock cameras without any public input. (Jade agreed to talk using only their first name for privacy concerns.)
“Some regulation has to be put in place,” Jade said. “Reacting to whatever secretive contract is signed in the future might work, but it is not ideal to have a revolving door of surveillance companies.”
A Flock Safety camera is aimed toward traffic traveling near a gas station, April 15, 2026, in Stoughton, Wis. (Angela Major / WPR)
In the absence of state restrictions, the ACLU of Wisconsin is advocating for local governments to adopt ordinances that give elected officials oversight over police surveillance. A model policy endorsed by the ACLU called Community Control Over Police Surveillance, or CCOPS, would require law enforcement to get approval from a city council or county commission before using new surveillance tools, as well as develop use policies and provide annual reports on them.
According to the ACLU, 26 jurisdictions nationwide already have a CCOPS ordinance in place, but the city of Madison is the only one in Wisconsin. (Madison police currently have no ALPR contract.) Dane County has no such ordinance, which gives the sheriff a lot more discretion.
Supporters say CCOPS ordinances allow cities to better vet the vendors that are hired, while also allowing residents to weigh in on what level of surveillance and risk they are willing to accept before the technology is used on them. McCray-Jones says elected officials can make informed decisions “instead of having to look into these technologies on their own and after the fact, in the aftermath when the damage is already done.”
But efforts to curtail AI surveillance in this way are hitting a wall in Milwaukee, Wisconsin’s most populous city, which became a cautionary tale for Flock when a police officer repeatedly used the cameras to stalk a romantic partner. The police chief quickly revoked most officers’ access but the city is continuing to use Flock cameras at this time.
In March, four members of the common council wrote a letter calling on the city to adopt a CCOPS policy. They also demanded other checks on surveillance, such as a requirement for officers to list a case number to justify searching the network, routine civilian hearings and independent audits, and a ban on ALPRs being used for immigration.
Even as they push for stronger oversight, though, a 2023 state law known as Act 12 has sharply limited Milwaukee’s ability to regulate police surveillance.
Though primarily a tax bill aimed at stabilizing pension debts, Act 12 forced Milwaukee to abandon civilian oversight in exchange for the funds. It stripped the Milwaukee Fire and Police Commission of its oversight authority, gave the police chief broad control over department policy and restricted the city council’s ability to set new rules.
Until then, the commission had offered a relatively strong model of civilian control, like when it banned officers from using chokeholds and no-knock warrants, putting it in the crosshairs of the local police union. Act 12 made it into a “rubber stamp” for the police.
Attendees protest facial recognition technology during the Feb. 5, 2026, meeting of the Milwaukee Fire and Police Commission. (Devin Blake / Milwaukee Neighborhood News Service)
Several council members told Bolts that Act 12 also interferes with their ability to forbid the Milwaukee Police Department from using Flock cameras, enact a CCOPS policy or set standards for how the city uses surveillance technology.
“We cannot propose that law here,” said Ald. Alex Brower, who cosigned the letter endorsing CCOPS. “It was extremely frustrating to find that out. There is less democratic control than there should be.”
Another council member who signed the letter, Sharlen Moore, echoed Brower’s concern, saying, “We do not have a lot of power and say-so around how they spend their budget.”
Moore and Brower are hopeful that the state could eventually restore some level of outside control over Milwaukee police; voters this fall are electing a new governor and Legislature, and Democrats hope to win control of the state government for the first time since 2010. But until the state takes action, the council members say they’ll have to rely on the police to voluntarily restrict their use of surveillance.
Brower told Bolts, “The police chief would not have banned facial recognition technology on his own if it hadn’t been for the groundswell of regular people.”
Now he hopes for a similar public outcry against ALPRs and other AI surveillance. Echoing the Madison-based advocates who say they’ll keep fighting contracts in Dane County, he said, “We need an active and engaged and organized population that is fighting for their liberties.”
Port Washington residents and environmental advocates urged Wisconsin regulators to deny air quality permits for a massive data center there and conduct further environmental review of the project.
Advancements in battery innovation are transforming both mobility and energy systems alike, according to Kurt Kelty, vice president of battery, propulsion, and sustainability at General Motors (GM). At the MIT Energy Initiative (MITEI) Fall Colloquium, Kelty explored how GM is bringing next-generation battery technologies from lab to commercialization, driving American battery innovation forward. The colloquium is part of the ongoing MITEI Presents: Advancing the Energy Transition speaker series.
At GM, Kelty’s team is primarily focused on three things: first, improving affordability to get more electric vehicles (EVs) on the road. “How do you drive down the cost?” Kelty asked the audience. “It's the batteries. The batteries make up about 30 percent of the cost of the vehicle.” Second, his team strives to improve battery performance, including charging speed and energy density. Third, they are working on localizing the supply chain. “We've got to build up our resilience and our independence here in North America, so we're not relying on materials coming from China,” Kelty explained.
To aid their efforts, resources are being poured into the virtualization space, significantly cutting down on time dedicated to research and development. Now, Kelty’s team can do modeling up front using artificial intelligence, reducing what previously would have taken months to a couple of days.
“If you want to modify … the nickel content ever so slightly, we can very quickly model: ‘OK, how’s that going to affect the energy density? The safety? How’s that going to affect the charge capability?’” said Kelty. “We can look at that at the cell level, then the pack level, then the vehicle level.”
Kelty revealed that they have found a solution that addresses affordability, accessibility, and commercialization: lithium manganese-rich (LMR) batteries. Previously, the industry looked to reduce costs by lowering the amount of cobalt in batteries by adding greater amounts of nickel. These high-nickel batteries are in most cars on the road in the United States due to their high range. LMR batteries, though, take things a step further by reducing the amount of nickel and adding more manganese, which drives the cost of batteries down even further while maintaining range.
Lithium-iron-phosphate (LFP) batteries are the chemistry of choice in China, known for low cost, high cycle life, and high safety. With LMR batteries, the cost is comparable to LFP with a range that is closer to high-nickel. “That’s what’s really a breakthrough,” said Kelty.
LMR batteries are not new, but there have been challenges to adopting them, according to Kelty. “People knew about it, but they didn’t know how to commercialize it. They didn’t know how to make it work in an EV,” he explained. Now that GM has figured out commercialization, they will be the first to market these batteries in their EVs in 2028.
Kelty also expressed excitement over the use of vehicle-to-grid technologies in the future. Using a bidirectional charger with a two-way flow of energy, EVs could charge, but also send power from their batteries back to the electrical grid. This would allow customers to charge “their vehicles at night when the electricity prices are really low, and they can discharge it during the day when electricity rates are really high,” he said.
In addition to working in the transportation sector, GM is exploring ways to extend their battery expertise into applications in grid-scale energy storage. “It’s a big market right now, but it’s growing very quickly because of the data center growth,” said Kelty.
When looking to the future of battery manufacturing and EVs in the United States, Kelty remains optimistic: “we’ve got the technology here to make it happen. We’ve always had the innovation here. Now, we’re getting more and more of the manufacturing. We’re getting that all together. We’ve got just tremendous opportunity here that I’m hopeful we’re going to be able to take advantage of and really build a massive battery industry here.”
This speaker series highlights energy experts and leaders at the forefront of the scientific, technological, and policy solutions needed to transform our energy systems. Visit MITEI’s Events page for more information on this and additional events.
Kurt Kelty (right), vice president of battery, propulsion, and sustainability at General Motors, joined MITEI's William Green at the 2025 MIT Energy Initiative Fall Colloquium. Kelty explained how GM is developing and commercializing next-generation battery technologies.
There is growing attention on the links between artificial intelligence and increased energy demands. But while the power-hungry data centers being built to support AI could potentially stress electricity grids, increase customer prices and service interruptions, and generally slow the transition to clean energy, the use of artificial intelligence can also help the energy transition.
For example, use of AI is reducing energy consumption and associated emissions in buildings, transportation, and industrial processes. In addition, AI is helping to optimize the design and siting of new wind and solar installations and energy storage facilities.
On electric power grids, using AI algorithms to control operations is helping to increase efficiency and reduce costs, integrate the growing share of renewables, and even predict when key equipment needs servicing to prevent failure and possible blackouts. AI can help grid planners schedule investments in generation, energy storage, and other infrastructure that will be needed in the future. AI is also helping researchers discover or design novel materials for nuclear reactors, batteries, and electrolyzers.
Researchers at MIT and elsewhere are actively investigating aspects of those and other opportunities for AI to support the clean energy transition. At its 2025 research conference, MITEI announced the Data Center Power Forum, a targeted research effort for MITEI member companies interested in addressing the challenges of data center power demand.
Controlling real-time operations
Customers generally rely on receiving a continuous supply of electricity, and grid operators get help from AI to make that happen — while optimizing the storage and distribution of energy from renewable sources at the same time.
But with more installation of solar and wind farms — both of which provide power in smaller amounts, and intermittently — and the growing threat of weather events and cyberattacks, ensuring reliability is getting more complicated. “That’s exactly where AI can come into the picture,” explains Anuradha Annaswamy, a senior research scientist in MIT’s Department of Mechanical Engineering and director of MIT’s Active-Adaptive Control Laboratory. “Essentially, you need to introduce a whole information infrastructure to supplement and complement the physical infrastructure.”
The electricity grid is a complex system that requires meticulous control on time scales ranging from decades all the way down to microseconds. The challenge can be traced to the basic laws of power physics: electricity supply must equal electricity demand at every instant, or generation can be interrupted. In past decades, grid operators generally assumed that generation was fixed — they could count on how much electricity each large power plant would produce — while demand varied over time in a fairly predictable way. As a result, operators could commission specific power plants to run as needed to meet demand the next day. If some outages occurred, specially designated units would start up as needed to make up the shortfall.
Today and in the future, that matching of supply and demand must still happen, even as the number of small, intermittent sources of generation grows and weather disturbances and other threats to the grid increase. AI algorithms provide a means of achieving the complex management of information needed to forecast within just a few hours which plants should run while also ensuring that the frequency, voltage, and other characteristics of the incoming power are as required for the grid to operate properly.
Moreover, AI can make possible new ways of increasing supply or decreasing demand at times when supplies on the grid run short. As Annaswamy points out, the battery in your electric vehicle (EV), as well as the one charged up by solar panels or wind turbines, can — when needed — serve as a source of extra power to be fed into the grid. And given real-time price signals, EV owners can choose to shift charging from a time when demand is peaking and prices are high to a time when demand and therefore prices are both lower. In addition, new smart thermostats can be set to allow the indoor temperature to drop or rise — a range defined by the customer — when demand on the grid is peaking. And data centers themselves can be a source of demand flexibility: selected AI calculations could be delayed as needed to smooth out peaks in demand. Thus, AI can provide many opportunities to fine-tune both supply and demand as needed.
In addition, AI makes possible “predictive maintenance.” Any downtime is costly for the company and threatens shortages for the customers served. AI algorithms can collect key performance data during normal operation and, when readings veer off from that normal, the system can alert operators that something might be going wrong, giving them a chance to intervene. That capability prevents equipment failures, reduces the need for routine inspections, increases worker productivity, and extends the lifetime of key equipment.
Annaswamy stresses that“figuring out how to architect this new power grid with these AI components will require many different experts to come together.” She notes that electrical engineers, computer scientists, and energy economists “will have to rub shoulders with enlightened regulators and policymakers to make sure that this is not just an academic exercise, but will actually get implemented. All the different stakeholders have to learn from each other. And you need guarantees that nothing is going to fail. You can’t have blackouts.”
Using AI to help plan investments in infrastructure for the future
Grid companies constantly need to plan for expanding generation, transmission, storage, and more, and getting all the necessary infrastructure built and operating may take many years, in some cases more than a decade. So, they need to predict what infrastructure they’ll need to ensure reliability in the future. “It’s complicated because you have to forecast over a decade ahead of time what to build and where to build it,” says Deepjyoti Deka, a research scientist in MITEI.
One challenge with anticipating what will be needed is predicting how the future system will operate. “That’s becoming increasingly difficult,” says Deka, because more renewables are coming online and displacing traditional generators. In the past, operators could rely on “spinning reserves,” that is, generating capacity that’s not currently in use but could come online in a matter of minutes to meet any shortfall on the system. The presence of so many intermittent generators — wind and solar — means there’s now less stability and inertia built into the grid. Adding to the complication is that those intermittent generators can be built by various vendors, and grid planners may not have access to the physics-based equations that govern the operation of each piece of equipment at sufficiently fine time scales. “So, you probably don’t know exactly how it’s going to run,” says Deka.
And then there’s the weather. Determining the reliability of a proposed future energy system requires knowing what it’ll be up against in terms of weather. The future grid has to be reliable not only in everyday weather, but also during low-probability but high-risk events such as hurricanes, floods, and wildfires, all of which are becoming more and more frequent, notes Deka. AI can help by predicting such events and even tracking changes in weather patterns due to climate change.
Deka points out another, less-obvious benefit of the speed of AI analysis. Any infrastructure development plan must be reviewed and approved, often by several regulatory and other bodies. Traditionally, an applicant would develop a plan, analyze its impacts, and submit the plan to one set of reviewers. After making any requested changes and repeating the analysis, the applicant would resubmit a revised version to the reviewers to see if the new version was acceptable. AI tools can speed up the required analysis so the process moves along more quickly. Planners can even reduce the number of times a proposal is rejected by using large language models to search regulatory publications and summarize what’s important for a proposed infrastructure installation.
Harnessing AI to discover and exploit advanced materials needed for the energy transition
“Use of AI for materials development is booming right now,” says Ju Li, MIT’s Carl Richard Soderberg Professor of Power Engineering. He notes two main directions.
First, AI makes possible faster physics-based simulations at the atomic scale. The result is a better atomic-level understanding of how composition, processing, structure, and chemical reactivity relate to the performance of materials. That understanding provides design rules to help guide the development and discovery of novel materials for energy generation, storage, and conversion needed for a sustainable future energy system.
And second, AI can help guide experiments in real time as they take place in the lab. Li explains: “AI assists us in choosing the best experiment to do based on our previous experiments and — based on literature searches — makes hypotheses and suggests new experiments.”
He describes what happens in his own lab. Human scientists interact with a large language model, which then makes suggestions about what specific experiments to do next. The human researcher accepts or modifies the suggestion, and a robotic arm responds by setting up and performing the next step in the experimental sequence, synthesizing the material, testing the performance, and taking images of samples when appropriate. Based on a mix of literature knowledge, human intuition, and previous experimental results, AI thus coordinates active learning that balances the goals of reducing uncertainty with improving performance. And, as Li points out, “AI has read many more books and papers than any human can, and is thus naturally more interdisciplinary.”
The outcome, says Li, is both better design of experiments and speeding up the “work flow.” Traditionally, the process of developing new materials has required synthesizing the precursors, making the material, testing its performance and characterizing the structure, making adjustments, and repeating the same series of steps. AI guidance speeds up that process, “helping us to design critical, cheap experiments that can give us the maximum amount of information feedback,” says Li.
“Having this capability certainly will accelerate material discovery, and this may be the thing that can really help us in the clean energy transition,” he concludes. “AI [has the potential to] lubricate the material-discovery and optimization process, perhaps shortening it from decades, as in the past, to just a few years.”
MITEI’s contributions
At MIT, researchers are working on various aspects of the opportunities described above. In projects supported by MITEI, teams are using AI to better model and predict disruptions in plasma flows inside fusion reactors — a necessity in achieving practical fusion power generation. Other MITEI-supported teams are using AI-powered tools to interpret regulations, climate data, and infrastructure maps in order to achieve faster, more adaptive electric grid planning. AI-guided development of advanced materials continues, with one MITEI project using AI to optimize solar cells and thermoelectric materials.
Other MITEI researchers are developing robots that can learn maintenance tasks based on human feedback, including physical intervention and verbal instructions. The goal is to reduce costs, improve safety, and accelerate the deployment of the renewable energy infrastructure. And MITEI-funded work continues on ways to reduce the energy demand of data centers, from designing more efficient computer chips and computing algorithms to rethinking the architectural design of the buildings, for example, to increase airflow so as to reduce the need for air conditioning.
In addition to providing leadership and funding for many research projects, MITEI acts as a convenor, bringing together interested parties to consider common problems and potential solutions. In May 2025, MITEI’s annual spring symposium — titled “AI and energy: Peril and promise” — brought together AI and energy experts from across academia, industry, government, and nonprofit organizations to explore AI as both a problem and a potential solution for the clean energy transition. At the close of the symposium, William H. Green, director of MITEI and Hoyt C. Hottel Professor in the MIT Department of Chemical Engineering, noted, “The challenge of meeting data center energy demand and of unlocking the potential benefits of AI to the energy transition is now a research priority for MITEI.”
On May 6, MIT AgeLab’s Advanced Vehicle Technology (AVT) Consortium, part of the MIT Center for Transportation and Logistics, celebrated 10 years of its global academic-industry collaboration. AVT was founded with the aim of developing new data that contribute to automotive manufacturers, suppliers, and insurers’ real-world understanding of how drivers use and respond to increasingly sophisticated vehicle technologies, such as assistive and automated driving, while accelerating the applied insight needed to advance design and development. The celebration event brought together stakeholders from across the industry for a set of keynote addresses and panel discussions on critical topics significant to the industry and its future, including artificial intelligence, automotive technology, collision repair, consumer behavior, sustainability, vehicle safety policy, and global competitiveness.
Bryan Reimer, founder and co-director of the AVT Consortium, opened the event by remarking that over the decade AVT has collected hundreds of terabytes of data, presented and discussed research with its over 25 member organizations, supported members’ strategic and policy initiatives, published select outcomes, and built AVT into a global influencer with tremendous impact in the automotive industry. He noted that current opportunities and challenges for the industry include distracted driving, a lack of consumer trust and concerns around transparency in assistive and automated driving features, and high consumer expectations for vehicle technology, safety, and affordability. How will industry respond? Major players in attendance weighed in.
In a powerful exchange on vehicle safety regulation, John Bozzella, president and CEO of the Alliance for Automotive Innovation, and Mark Rosekind, former chief safety innovation officer of Zoox, former administrator of the National Highway Traffic Safety Administration, and former member of the National Transportation Safety Board, challenged industry and government to adopt a more strategic, data-driven, and collaborative approach to safety. They asserted that regulation must evolve alongside innovation, not lag behind it by decades. Appealing to the automakers in attendance, Bozzella cited the success of voluntary commitments on automatic emergency braking as a model for future progress. “That’s a way to do something important and impactful ahead of regulation.” They advocated for shared data platforms, anonymous reporting, and a common regulatory vision that sets safety baselines while allowing room for experimentation. The 40,000 annual road fatalities demand urgency — what’s needed is a move away from tactical fixes and toward a systemic safety strategy. “Safety delayed is safety denied,” Rosekind stated. “Tell me how you’re going to improve safety. Let’s be explicit.”
Drawing inspiration from aviation’s exemplary safety record, Kathy Abbott, chief scientific and technical advisor for the Federal Aviation Administration, pointed to a culture of rigorous regulation, continuous improvement, and cross-sectoral data sharing. Aviation’s model, built on highly trained personnel and strict predictability standards, contrasts sharply with the fragmented approach in the automotive industry. The keynote emphasized that a foundation of safety culture — one that recognizes that technological ability alone isn’t justification for deployment — must guide the auto industry forward. Just as aviation doesn’t equate absence of failure with success, vehicle safety must be measured holistically and proactively.
With assistive and automated driving top of mind in the industry, Pete Bigelow of Automotive News offered a pragmatic diagnosis. With companies like Ford and Volkswagen stepping back from full autonomy projects like Argo AI, the industry is now focused on Level 2 and 3 technologies, which refer to assisted and automated driving, respectively. Tesla, GM, and Mercedes are experimenting with subscription models for driver assistance systems, yet consumer confusion remains high. JD Power reports that many drivers do not grasp the differences between L2 and L2+, or whether these technologies offer safety or convenience features. Safety benefits have yet to manifest in reduced traffic deaths, which have risen by 20 percent since 2020. The recurring challenge: L3 systems demand that human drivers take over during technical difficulties, despite driver disengagement being their primary benefit, potentially worsening outcomes. Bigelow cited a quote from Bryan Reimer as one of the best he’s received in his career: “Level 3 systems are an engineer’s dream and a plaintiff attorney’s next yacht,” highlighting the legal and design complexity of systems that demand handoffs between machine and human.
In terms of the impact of AI on the automotive industry, Mauricio Muñoz, senior research engineer at AI Sweden, underscored that despite AI’s transformative potential, the automotive industry cannot rely on general AI megatrends to solve domain-specific challenges. While landmark achievements like AlphaFold demonstrate AI’s prowess, automotive applications require domain expertise, data sovereignty, and targeted collaboration. Energy constraints, data firewalls, and the high costs of AI infrastructure all pose limitations, making it critical that companies fund purpose-driven research that can reduce costs and improve implementation fidelity. Muñoz warned that while excitement abounds — with some predicting artificial superintelligence by 2028 — real progress demands organizational alignment and a deep understanding of the automotive context, not just computational power.
Turning the focus to consumers, a collision repair panel drawing Richard Billyeald from Thatcham Research, Hami Ebrahimi from Caliber Collision, and Mike Nelson from Nelson Law explored the unintended consequences of vehicle technology advances: spiraling repair costs, labor shortages, and a lack of repairability standards. Panelists warned that even minor repairs for advanced vehicles now require costly and complex sensor recalibrations — compounded by inconsistent manufacturer guidance and no clear consumer alerts when systems are out of calibration. The panel called for greater standardization, consumer education, and repair-friendly design. As insurance premiums climb and more people forgo insurance claims, the lack of coordination between automakers, regulators, and service providers threatens consumer safety and undermines trust. The group warned that until Level 2 systems function reliably and affordably, moving toward Level 3 autonomy is premature and risky.
While the repair panel emphasized today’s urgent challenges, other speakers looked to the future. Honda’s Ryan Harty, for example, highlighted the company’s aggressive push toward sustainability and safety. Honda aims for zero environmental impact and zero traffic fatalities, with plans to be 100 percent electric by 2040 and to lead in energy storage and clean power integration. The company has developed tools to coach young drivers and is investing in charging infrastructure, grid-aware battery usage, and green hydrogen storage. “What consumers buy in the market dictates what the manufacturers make,” Harty noted, underscoring the importance of aligning product strategy with user demand and environmental responsibility. He stressed that manufacturers can only decarbonize as fast as the industry allows, and emphasized the need to shift from cost-based to life-cycle-based product strategies.
Finally, a panel involving Laura Chace of ITS America, Jon Demerly of Qualcomm, Brad Stertz of Audi/VW Group, and Anant Thaker of Aptiv covered the near-, mid-, and long-term future of vehicle technology. Panelists emphasized that consumer expectations, infrastructure investment, and regulatory modernization must evolve together. Despite record bicycle fatality rates and persistent distracted driving, features like school bus detection and stop sign alerts remain underutilized due to skepticism and cost. Panelists stressed that we must design systems for proactive safety rather than reactive response. The slow integration of digital infrastructure — sensors, edge computing, data analytics — stems not only from technical hurdles, but procurement and policy challenges as well.
Reimer concluded the event by urging industry leaders to re-center the consumer in all conversations — from affordability to maintenance and repair. With the rising costs of ownership, growing gaps in trust in technology, and misalignment between innovation and consumer value, the future of mobility depends on rebuilding trust and reshaping industry economics. He called for global collaboration, greater standardization, and transparent innovation that consumers can understand and afford. He highlighted that global competitiveness and public safety both hang in the balance. As Reimer noted, “success will come through partnerships” — between industry, academia, and government — that work toward shared investment, cultural change, and a collective willingness to prioritize the public good.
The cleantech world is experiencing a quiet revolution. Artificial intelligence is no longer knocking at the door, it’s quietly remodeling the entire house....
Car design is an iterative and proprietary process. Carmakers can spend several years on the design phase for a car, tweaking 3D forms in simulations before building out the most promising designs for physical testing. The details and specs of these tests, including the aerodynamics of a given car design, are typically not made public. Significant advances in performance, such as in fuel efficiency or electric vehicle range, can therefore be slow and siloed from company to company.
MIT engineers say that the search for better car designs can speed up exponentially with the use of generative artificial intelligence tools that can plow through huge amounts of data in seconds and find connections to generate a novel design. While such AI tools exist, the data they would need to learn from have not been available, at least in any sort of accessible, centralized form.
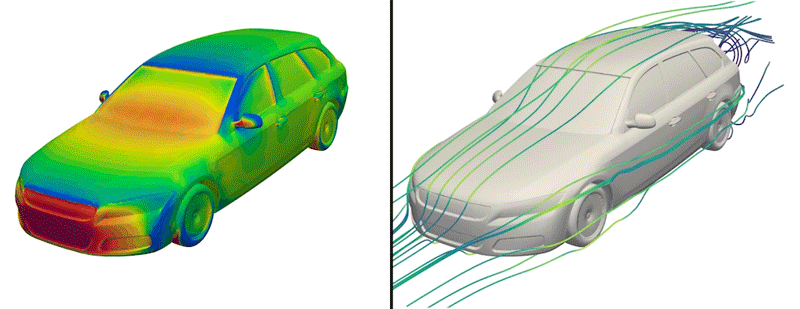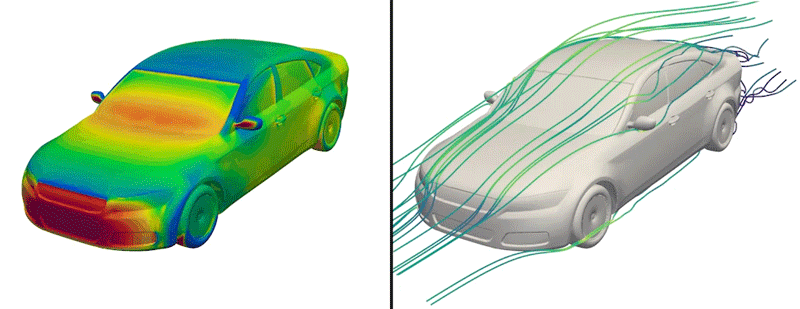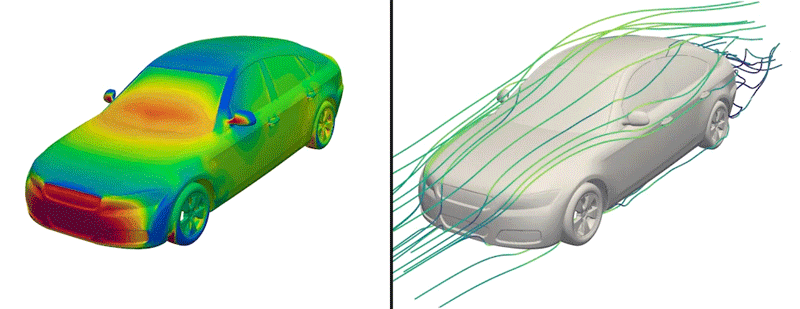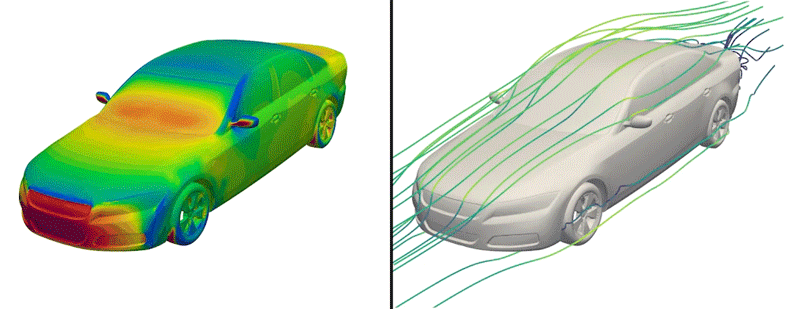
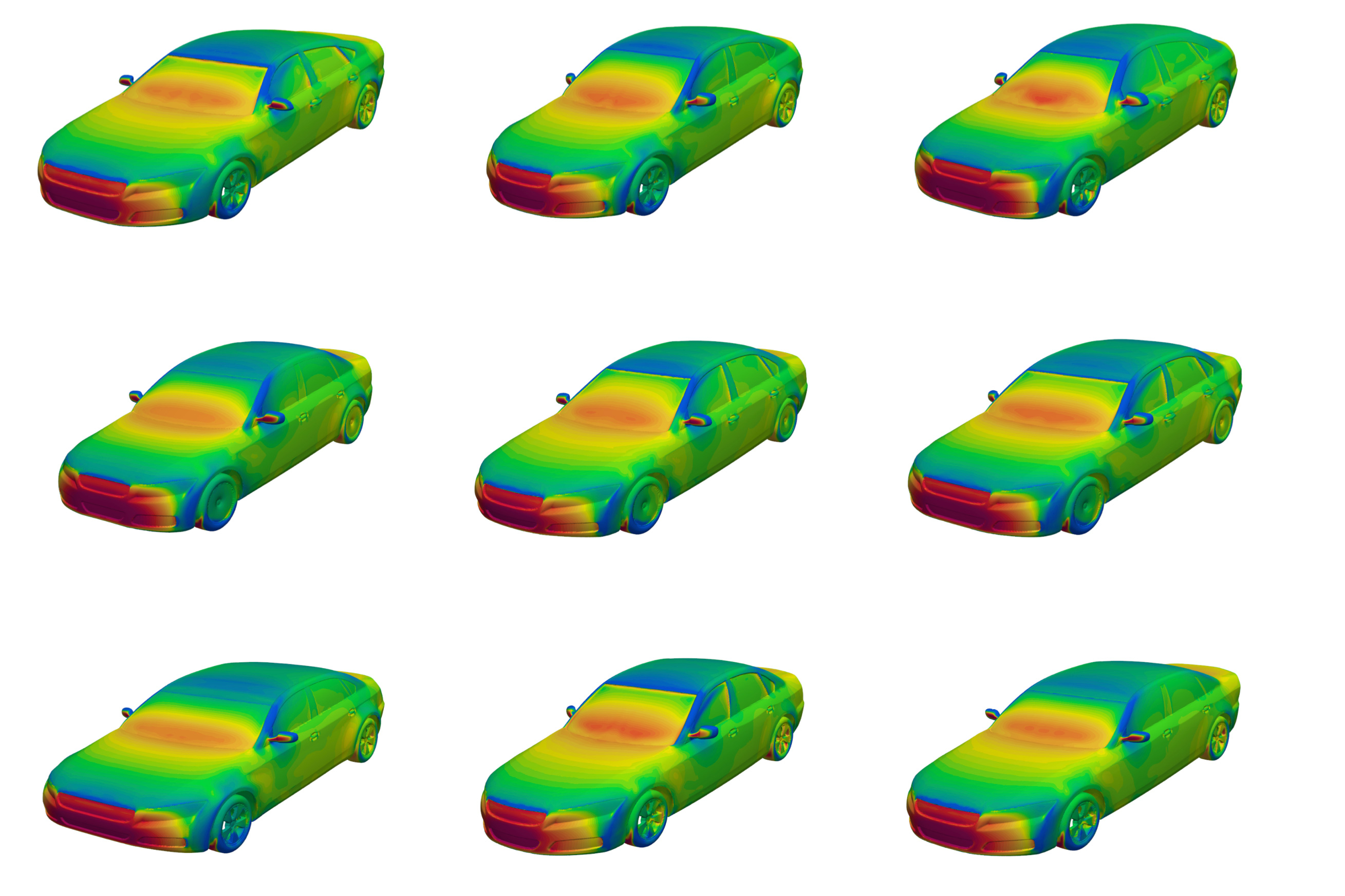
But now, the engineers have made just such a dataset available to the public for the first time. Dubbed DrivAerNet++, the dataset encompasses more than 8,000 car designs, which the engineers generated based on the most common types of cars in the world today. Each design is represented in 3D form and includes information on the car’s aerodynamics — the way air would flow around a given design, based on simulations of fluid dynamics that the group carried out for each design.
Each of the dataset’s 8,000 designs is available in several representations, such as mesh, point cloud, or a simple list of the design’s parameters and dimensions. As such, the dataset can be used by different AI models that are tuned to process data in a particular modality.
DrivAerNet++ is the largest open-source dataset for car aerodynamics that has been developed to date. The engineers envision it being used as an extensive library of realistic car designs, with detailed aerodynamics data that can be used to quickly train any AI model. These models can then just as quickly generate novel designs that could potentially lead to more fuel-efficient cars and electric vehicles with longer range, in a fraction of the time that it takes the automotive industry today.
“This dataset lays the foundation for the next generation of AI applications in engineering, promoting efficient design processes, cutting R&D costs, and driving advancements toward a more sustainable automotive future,” says Mohamed Elrefaie, a mechanical engineering graduate student at MIT.
Elrefaie and his colleagues will present a paper detailing the new dataset, and AI methods that could be applied to it, at the NeurIPS conference in December. His co-authors are Faez Ahmed, assistant professor of mechanical engineering at MIT, along with Angela Dai, associate professor of computer science at the Technical University of Munich, and Florin Marar of BETA CAE Systems.
Filling the data gap
Ahmed leads the Design Computation and Digital Engineering Lab (DeCoDE) at MIT, where his group explores ways in which AI and machine-learning tools can be used to enhance the design of complex engineering systems and products, including car technology.
“Often when designing a car, the forward process is so expensive that manufacturers can only tweak a car a little bit from one version to the next,” Ahmed says. “But if you have larger datasets where you know the performance of each design, now you can train machine-learning models to iterate fast so you are more likely to get a better design.”
And speed, particularly for advancing car technology, is particularly pressing now.
“This is the best time for accelerating car innovations, as automobiles are one of the largest polluters in the world, and the faster we can shave off that contribution, the more we can help the climate,” Elrefaie says.
In looking at the process of new car design, the researchers found that, while there are AI models that could crank through many car designs to generate optimal designs, the car data that is actually available is limited. Some researchers had previously assembled small datasets of simulated car designs, while car manufacturers rarely release the specs of the actual designs they explore, test, and ultimately manufacture.
The team sought to fill the data gap, particularly with respect to a car’s aerodynamics, which plays a key role in setting the range of an electric vehicle, and the fuel efficiency of an internal combustion engine. The challenge, they realized, was in assembling a dataset of thousands of car designs, each of which is physically accurate in their function and form, without the benefit of physically testing and measuring their performance.
To build a dataset of car designs with physically accurate representations of their aerodynamics, the researchers started with several baseline 3D models that were provided by Audi and BMW in 2014. These models represent three major categories of passenger cars: fastback (sedans with a sloped back end), notchback (sedans or coupes with a slight dip in their rear profile) and estateback (such as station wagons with more blunt, flat backs). The baseline models are thought to bridge the gap between simple designs and more complicated proprietary designs, and have been used by other groups as a starting point for exploring new car designs.
Library of cars
In their new study, the team applied a morphing operation to each of the baseline car models. This operation systematically made a slight change to each of 26 parameters in a given car design, such as its length, underbody features, windshield slope, and wheel tread, which it then labeled as a distinct car design, which was then added to the growing dataset. Meanwhile, the team ran an optimization algorithm to ensure that each new design was indeed distinct, and not a copy of an already-generated design. They then translated each 3D design into different modalities, such that a given design can be represented as a mesh, a point cloud, or a list of dimensions and specs.
The researchers also ran complex, computational fluid dynamics simulations to calculate how air would flow around each generated car design. In the end, this effort produced more than 8,000 distinct, physically accurate 3D car forms, encompassing the most common types of passenger cars on the road today.
To produce this comprehensive dataset, the researchers spent over 3 million CPU hours using the MIT SuperCloud, and generated 39 terabytes of data. (For comparison, it’s estimated that the entire printed collection of the Library of Congress would amount to about 10 terabytes of data.)
The engineers say that researchers can now use the dataset to train a particular AI model. For instance, an AI model could be trained on a part of the dataset to learn car configurations that have certain desirable aerodynamics. Within seconds, the model could then generate a new car design with optimized aerodynamics, based on what it has learned from the dataset’s thousands of physically accurate designs.
The researchers say the dataset could also be used for the inverse goal. For instance, after training an AI model on the dataset, designers could feed the model a specific car design and have it quickly estimate the design’s aerodynamics, which can then be used to compute the car’s potential fuel efficiency or electric range — all without carrying out expensive building and testing of a physical car.
“What this dataset allows you to do is train generative AI models to do things in seconds rather than hours,” Ahmed says. “These models can help lower fuel consumption for internal combustion vehicles and increase the range of electric cars — ultimately paving the way for more sustainable, environmentally friendly vehicles.”
“The dataset is very comprehensive and consists of a diverse set of modalities that are valuable to understand both styling and performance,” says Yanxia Zhang, a senior machine learning research scientist at Toyota Research Institute, who was not involved in the study.
This work was supported, in part, by the German Academic Exchange Service and the Department of Mechanical Engineering at MIT.
In a new dataset that includes more than 8,000 car designs, MIT engineers simulated the aerodynamics for a given car shape, which they represent in various modalities, including “surface fields.”